
.avif)
Observability data is now a commodity. The agents to collect metrics, logs and traces are freely available from both open source and commercial vendors. Collecting the data is the easy part, the tricky bit is processing the enormous amount of data generated and turning it into actionable information. This is where the platforms from the usual suspects come into play; at a cost. That cost is directly proportional to the volume of data processed. The vendors like to generate fear, uncertainty and doubt about how essential every byte of that data is; the piece of data you chose not to send will be the piece of data you need to solve an issue. Of course, the more you send, the more it costs and the greater the return to the vendor’s shareholders. Once committed to a platform it takes considerable effort to break free, until now.
Grepr Gives You Options
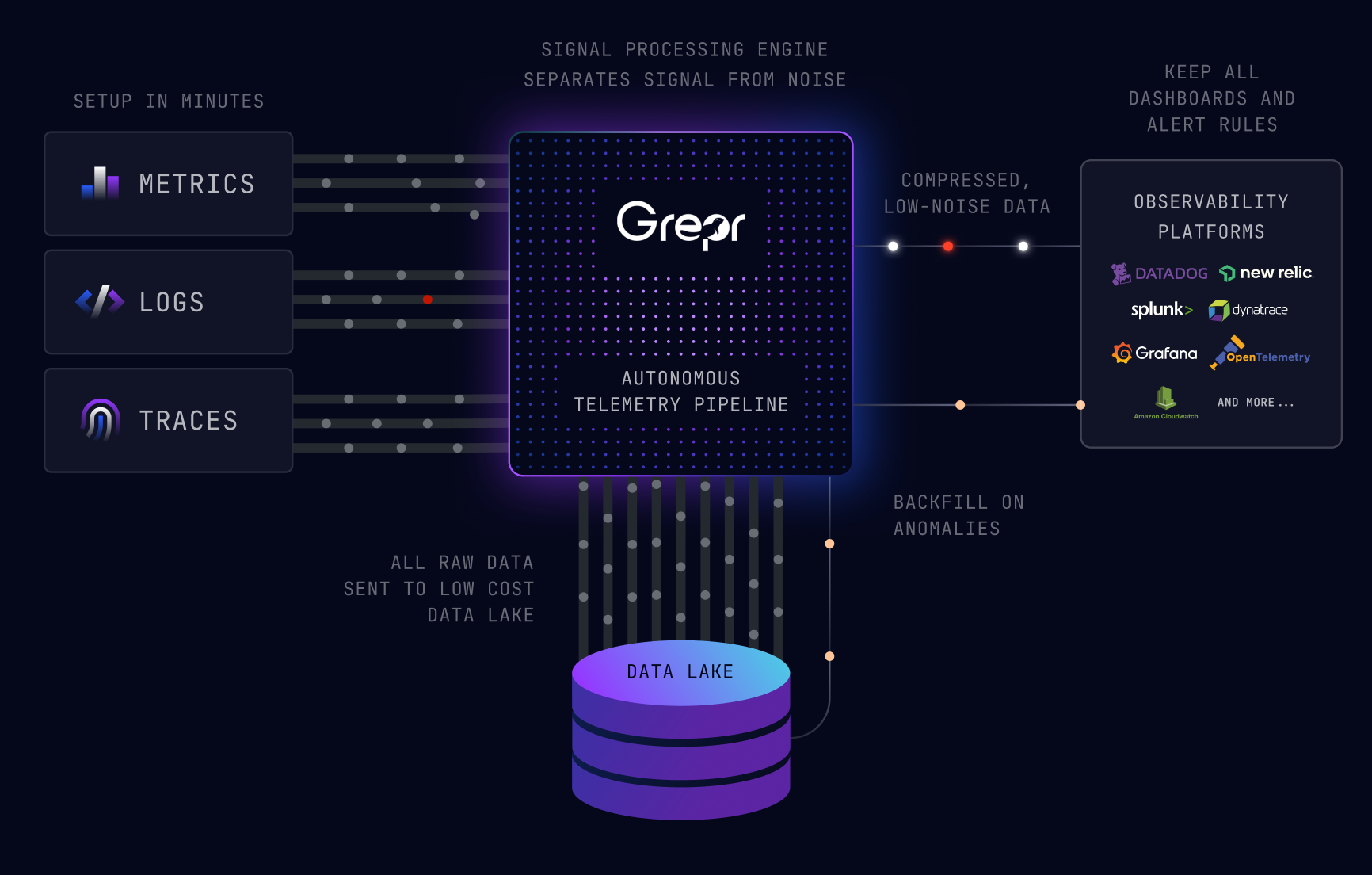
Grepr slips in like a shim between the agents collecting the data and the observability platform processing the data. Using AI (machine learning) Grepr automatically identifies similar patterns across the data then uses these to send summaries for frequent entries while letting unique entries straight through; reducing data by 90%.

No data is ever discarded, all data sent to Grepr is retained in low cost storage where it can be queried and optionally backfilled (on demand) to the observability platform. Grepr provides 100% insight with 10% of the data.
A Grepr pipeline configures how this should happen. It defines the source(s) of the data, for example it could include an endpoint for Datadog and Open Telemetry agents. It specifies which low cost storage to use for all the data received. Finally it sets the ultimate destination(s) for the processed data, for example New Relic and Splunk. Optionally it may configure static rules to always include/exclude certain data and/or transform/enhance data.
This may be an extreme example but it shows what is possible when mixing and matching observability platforms.
No Longer Shackled
Changing the observability platform you use is typically a non-trivial task. Redeploying innumerable application services to change the instrumentation code, deploying and configuring new agents to ship the data. Running two observability platforms simultaneously during and after the migration to ensure no data is lost and ensuring continuity with the existing operational processes. It’s all a lot of effort and presents an insurmountable barrier for most organisations.
With Grepr the observability platform used to process the data is independent of the agents used to ship the data. Using multiple Grepr pipelines observability data can be incrementally moved from one backend to another with zero risk of losing any data; all data is retained in low cost storage. Utilising Grepr Dynamic Backfill the new observability platform can soon be up and running complete with historical data, reducing the duration needed to run two platforms simultaneously.
The highly configurable Grepr pipelines release you from vendor lock-in as well as saving 90% on platform costs by optimising the data. Exploiting low cost storage for all data means you no longer have to balance retention against cost; keep more data for longer at a lower cost. You now have the flexibility and control to manage and arbitrate where your observability data is processed
More blog posts
All blog posts
How Envoy Reduced Observability Data Volume by 90% Without Touching a Single Dashboard
Grepr Just Launched a Free Tier: Reduce telemetry noise by 90%

Grepr Wins the 2026 Intellyx Digital Innovator Award for Observability Cost Reduction
Get started free and see Grepr in action in 30 minutes.
