
WHAT IF you could collect and find detailed data on every execution in your application and retroactively go back in time to understand exactly what happened when a user experienced an issue or when an application had slowdowns? It would be trivial to identify where things went wrong, your MTTR would drop. When APM was first introduced, in the world of Services-Oriented Architectures (SOA) and 3-tiered systems, this seemed very possible. But then Netflix introduced microservices, and Docker and Kubernetes became the de facto way of running any real application at scale. It was no longer cost-effective or even possible to store every single transaction at scale for large applications.
The dream seemed to have died.
Distributed tracing is essential for managing modern microservices based applications, but the data volume can be overwhelming. To manage costs, most teams rely on sampling, which reduces the fidelity and effectiveness of both monitoring and root cause analysis. Grepr has solved this dilemma.
There are two techniques used by today's tools to monitor transactions running through your application - head sampling and tail sampling. With head sampling, the decision to keep or drop a trace is made at the very beginning, when the first span (the "root" span) is created. This approach is simple and resource-efficient as it doesn't require buffering traces. However, by blindly applying randomness it cannot take into account data that comes later in the trace's lifecycle, such as errors, high latency, or specific downstream events. It can miss important traces!
Tail sampling is the current state-of-the-art for monitoring transactions. In this approach, a decision to keep a trace is made only after all its constituent spans have been collected and the full trace has been assembled in the APM tool backend. This allows for sampling decisions based on the overall characteristics of the trace, such as its total duration or whether it contains errors. A common implementation of tail sampling involves grouping or "bucketing" traces by a common attribute, typically the trace name (e.g., the HTTP request URI POST /api/users). Policies are then applied to these buckets, such as "collect 100% of error traces" or "sample 5% of traces with a duration greater than 500ms."
Because tail sampling uses simple bucketing constructs based on the root span, it can miss important structural information. If application execution could take multiple paths after starting at an endpoint, and each path has a different performance profile, lumping all these paths together in the same sampling bucket is problematic. The definition of a “fast” or “slow” trace might be different for each path. It would then be sampling incorrectly and again missing issues. The one unique path that a particular user took and ended up with an unexpected outcome would still be likely lost if its performance looked like others in its coarse-grained bucket.
Further, when you implement tail sampling at the observability platform the cost remains high because most vendors charge for all trace spans received, independently of whether they are sampled.
Because of these shortcomings, both of these approaches create anxiety and real issues. How do you know that the traces you really need to troubleshoot a problem will be collected?
Traditional tail samplers group traces by a simple dimension, usually the root span name (e.g., POST /users). The problem is that a single endpoint can mask dozens of completely different execution paths based on feature flags, conditional logic, or data variations.
The performance of a subset of traces following a different execution path can be overshadowed by a set of traces following another path. For example, creating a user with complex permissioning policies might take longer than one without those policies. And that’s normal. But then, this skews the definition of “normal” for the user creation endpoint.
This causes signal dilution, statistically burying critical performance anomalies and making them nearly impossible to find and wasting hours of time. And when combined with sampling, you will miss valuable information.
Can we do better?
Grepr’s Innovation: High-Fidelity Structural Signatures
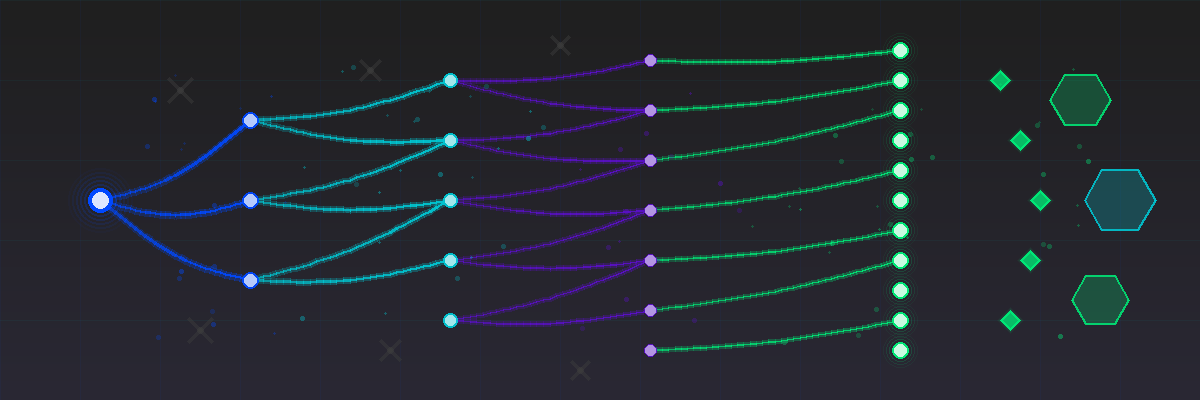
Above: Two traces that start at the same place but take different paths

Leveraging our stateful Intelligent Observability Data Engine and its ability to identify patterns at scale in real-time, we’re introducing Signature Sampling for traces, a novel approach that eliminates coarse bucketing by inspecting every trace and giving it a unique structural signature
This signature is a canonical, deterministic record of the trace’s exact execution path.
- Path Mapping: The system recursively traverses the entire span hierarchy, capturing the flow of control and service calls.
- Deterministic Integrity: To ensure consistency, it uses loop collapsing (to prevent noisy signatures from repeated operations) and deterministic serialization (to guarantee the same structure always yields the same signature).
The result is that every distinct path through your system, whether it’s a standard success flow or a rare complex error path, is assigned its own unique signature and inspected for performance deviations and errors.
Re-imaging APM with Upstream Intelligence
With Structural Signatures, Grepr can now assign a bucket at a much finer granularity, one that’s more aligned to the information in each trace. It has moved the act of sorting signal from noise upstream in the processing sequence; before incurring the cost of storing traces. Once traces are bucketed by their structural signatures, Grepr can sample them based on uniqueness AND performance, dramatically reducing the volume of traces forwarded to your existing observability tools, yet ensuring that you continue to have broad APM coverage to power existing workflows.
The Benefits: Unlocked Observability
By deploying Grepr’s Signature Sampling, you gain:
- High-Fidelity Signal: Anomalies are no longer lost. When a trace is slow, it is compared only against others that followed the same execution path, making outliers immediately obvious.
- Automated Path Discovery: The system automatically identifies and tracks new execution paths as your code changes (e.g., a new feature flag is enabled), without any manual configuration or tuning.
- Cross-Correlation with Log Reduction: By combining and linking logs with traces, Grepr’s Log Reduction can ensure that all traces that are sampled and forward to your observability tools also have full logs for troubleshooting.
- Cost-Efficient Precision: By intelligently prioritizing and keeping only the most valuable and diverse data for every path, you can dramatically reduce storage and indexing costs while improving the quality and breadth of your monitoring.
- No data is lost: Grepr still stores all your traces into low-cost storage so you can go back, search them, and backfill them to your observability tools.
- No migrations: Grepr works with your existing observability tools!
This approach brings true performance isolation and surgical precision to distributed tracing, ensuring that the valuable data you need to debug problems is always available, while simultaneously dramatically reducing the amounts of tracing data needing to be persisted in the observability platform.
See how Grepr’s Signature Sampling changes what’s possible in APM. Start your free trial today and experience high-fidelity observability without the noise or cost.
FAQs (Frequently Asked Questions)
What is Grepr's Innovation in Application Performance Monitoring (APM)?
Grepr introduces High-Fidelity Structural Signatures, a cutting-edge approach that enhances APM by providing precise and detailed trace analysis.
How do Structural Signatures improve trace analysis in Grepr?
Structural Signatures allow Grepr to differentiate traces that start at the same point but follow different paths, enabling more accurate bucket assignment and insightful performance monitoring.
What does 'Re-imaging APM with Upstream Intelligence' mean in Grepr's context?
It refers to leveraging advanced upstream data insights through Structural Signatures to redefine how application performance is observed and analyzed, leading to smarter diagnostics and optimization.
What are the benefits of deploying Grepr's Signature Sampling?
By using Signature Sampling, users unlock enhanced observability, gaining high-fidelity insights into application behavior, which facilitates quicker issue detection and improved system reliability.
How does Grepr's approach unlock observability in applications?
Grepr's method provides detailed structural signatures of traces, enabling comprehensive visibility into application workflows and performance bottlenecks that traditional APM tools might miss.
Why is high-fidelity important in structural signatures for APM?
High-fidelity ensures that the structural signatures accurately represent the true behavior of application traces, allowing for precise monitoring, better anomaly detection, and more effective performance tuning.
More blog posts
All blog posts
Grepr Wins the 2026 Intellyx Digital Innovator Award for Observability Cost Reduction

What We Heard at Observability Summit 2026
.png)
Sawmills vs Grepr: Telemetry Pipeline Comparison for SREs
Get started free and see Grepr in action in 30 minutes.
