

I watched an episode of WWT's AI Proving Ground podcast last week that got me thinking. The episode featured Lynn Comp from Intel's AI Center of Excellence and Mike Trojecki from WWT's AI go-to-market team. The whole conversation centered on a tension I see play out constantly: enterprises are scaling AI quickly, but many of the infrastructure decisions behind that scale don't actually match the workloads they're supporting.
Lynn had this line that stuck with me. She compared the default enterprise approach to AI infrastructure to "driving a Ferrari to get groceries." You've got document summarization running on hardware built for training frontier models. Call centers processing natural language on GPU clusters when CPUs with light accelerators would handle it fine. She mentioned a 20,000-person call center running entirely on CPU servers. That's real.
The consequences aren't hypothetical. She talked about one of the leading tech CEOs admitting they have GPUs sitting in inventory because they can't power them on. Ordered first, figured out capacity second. That pattern should sound familiar to anyone who's watched an enterprise technology buildout.
The parallel to observability
Here's why I'm writing about this and not just sharing the link on LinkedIn.
The same pattern Lynn described for compute infrastructure is also happening in observability.
Teams default to sending everything to their observability platform: all the logs, all the traces, all the metrics, with no filtering and no prioritization. The assumption is that more data equals better reliability. Just like ordering GPUs you can't power, the result is massive bills for data that never gets queried, dashboards that choke because there's too much noise, and engineers stuck choosing between what they can afford to monitor and what they actually need to see.
Lynn put it well when she talked about the importance of "matching the need for the capability to what you have available before you start over-engineering." That principle applies directly to how organizations handle telemetry data. Most teams have never stopped to ask which how their logs are getting used.
Right-sizing doesn't mean flying blind
One thing I appreciated about the podcast was that nobody was arguing for doing less. The argument was for being intentional. Mike made the point that the value is in "combining the strengths of all those different types of processors" and treating it as an ecosystem. CPU for the workloads that fit. GPU where the task demands it. Specialized accelerators where they make sense.
Observability should work the same way. You need full visibility during incidents. You do not need to pay premium ingestion rates for millions of identical health check logs that repeat every 30 seconds. The question is how do you do that in an easy way?
That's the problem we're solving at Grepr. Grepr sits between the sources and the sinks, and in real time, distinguishes signal from noise. Low-noise data passes through immediately. Repeated patterns get summarized. Raw data goes to your data lake, where you can access it anytime. Teams see 80 to 99 percent volume reduction without losing their ability to respond to incidents and without impacting alerting.
The agentic future makes this worse before it gets better
The podcast spent a lot of time on agentic AI, and for good reason. Lynn and Mike both flagged that agentic systems will bring far more diversity in models, data sources, and workloads. That translates directly to telemetry volume. New agents, new architectures, new orchestration layers, all of it generating logs and traces that land in your observability platform at whatever per-GB rate you're paying.
Mike raised a critical point about governance and traceability for agents. You need digital credentials, audit trails, and intervention protocols. All of that generates data. And all of that data has to go somewhere.
If your observability costs scale linearly with the amount of infrastructure you're running, the math on agentic AI gets ugly fast. Grepr flattens the curve.
The discipline question
The podcast host wrapped the episode with this observation: the constraint isn't imagination, it's discipline. I agree. And I'd extend it. The discipline to right-size your compute is the same discipline required to right-size your observability data. Both require you to stop defaulting to the most expensive option and start asking what the actual workload demands.
Lynn mentioned Intel deploying sentiment analysis across manufacturing tool flows using NLP on CPUs for predictive maintenance. No GPU required. High ROI. That kind of thinking, applied to your telemetry pipeline, is where observability needs to go next.
The episode is worth 30 minutes of your time. You can find it on WWT's AI Proving Ground podcast. And if the infrastructure efficiency argument resonates, it's probably worth asking the same questions about your observability spend.
Frequently Asked Questions
1. What does it mean to right-size observability data?
Right-sizing observability data means matching the volume and resolution of logs, metrics, and traces you ingest to the actual operational needs of your team. Instead of sending all telemetry to a single platform at full fidelity, right-sizing involves filtering redundant data, summarizing repeated patterns, and routing raw logs to low-cost storage while keeping critical signals available for alerting and incident response.
2. Why are observability costs rising so fast?
Observability costs are rising because telemetry volume grows with every new service, agent, and infrastructure layer an organization deploys. Most teams ingest everything by default, including repetitive health checks, duplicate log lines, and low-value traces, at per-GB pricing. As architectures become more complex, particularly with microservices and agentic AI, the volume of generated data scales faster than the budget to store and query it.
3. How can you reduce observability spend without losing visibility?
The most effective approach is to process telemetry data before it reaches your observability platform. This means passing high-signal data through immediately, summarizing repeated patterns, and sending raw data to a low-cost data lake for on-demand access. Teams that take this approach typically see 80 to 99 percent volume reduction while maintaining full incident response capability and uninterrupted alerting.
4. What is the impact of agentic AI on observability and monitoring costs?
Agentic AI systems introduce new models, orchestration layers, and autonomous workflows that each generate their own logs, traces, and audit trails. Governance requirements like digital credentials and intervention protocols add further telemetry. If observability costs scale linearly with infrastructure volume, agentic AI adoption can drive monitoring spend to unsustainable levels without a data optimization layer in place.
More blog posts
All blog posts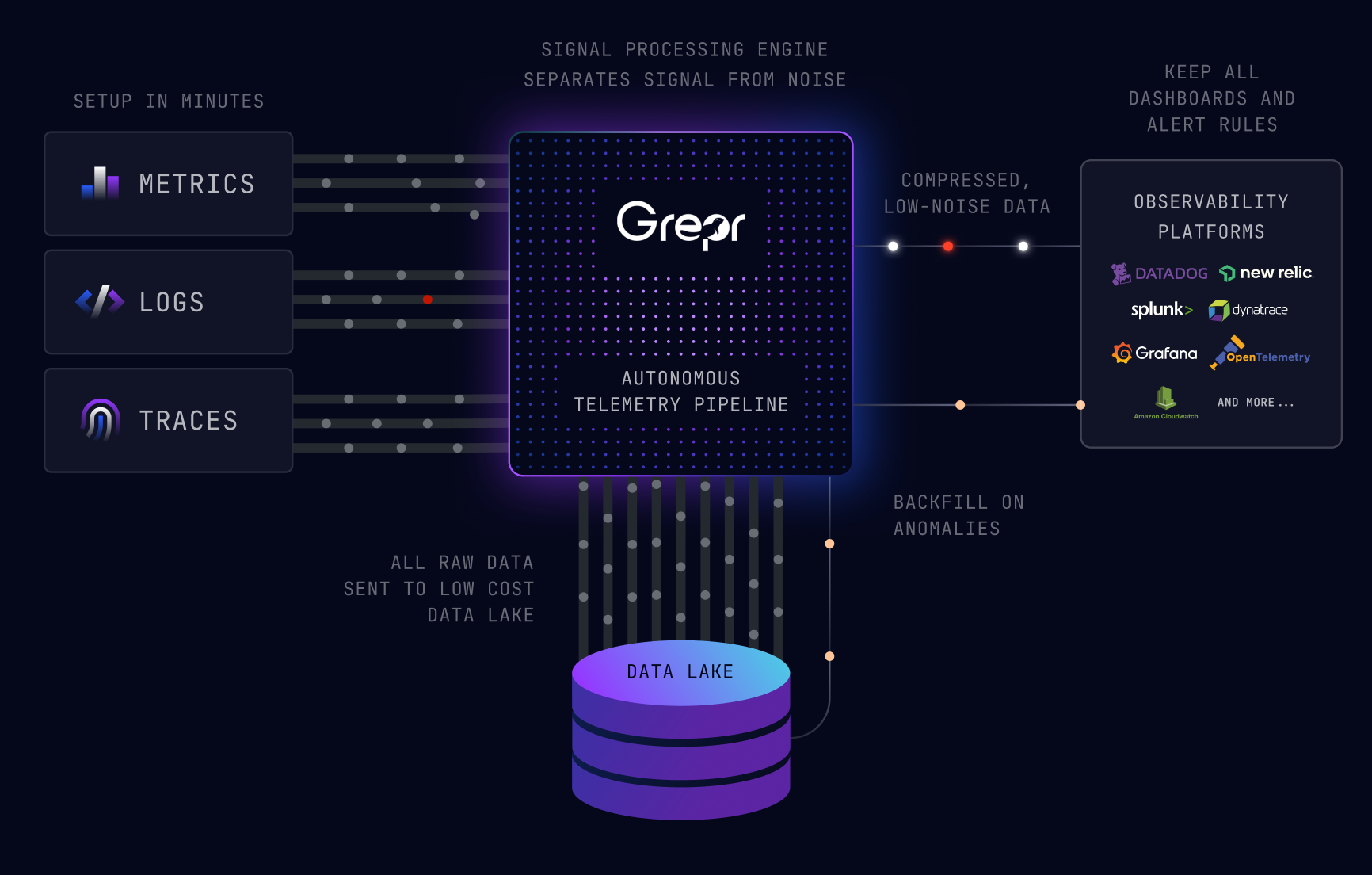
Grepr Just Launched a Free Tier: Reduce telemetry noise by 90%

Grepr Wins the 2026 Intellyx Digital Innovator Award for Observability Cost Reduction

What We Heard at Observability Summit 2026
Get started free and see Grepr in action in 30 minutes.
