Comparisons
How Grepr and Edge Delta Take Different Paths to the Same Goal
.png)
Edge Delta and Grepr both promise to help engineering teams get control of observability costs through smarter data processing. Both use AI to analyze data streams. Both sit between your infrastructure and your observability platform. On paper, they sound similar.
In practice, they take fundamentally different approaches to the problem.
Edge Delta builds an analytics layer on top of your observability data, with pipeline filtering as part of a broader platform. Grepr takes a narrower approach: cut data volume by 90% or more without asking engineers to build or maintain pipeline rules.
Here's how they actually compare.
Edge Delta analyzes observability data streams in an attempt to automatically identify emerging issues. In addition, it enables engineers to search observability data via natural language queries. All data processing by Edge Delta is performed in configured pipelines. Pipeline definitions allow observability engineers to configure and manage observability data flow from and to various sources and sinks, optionally with additional processing.
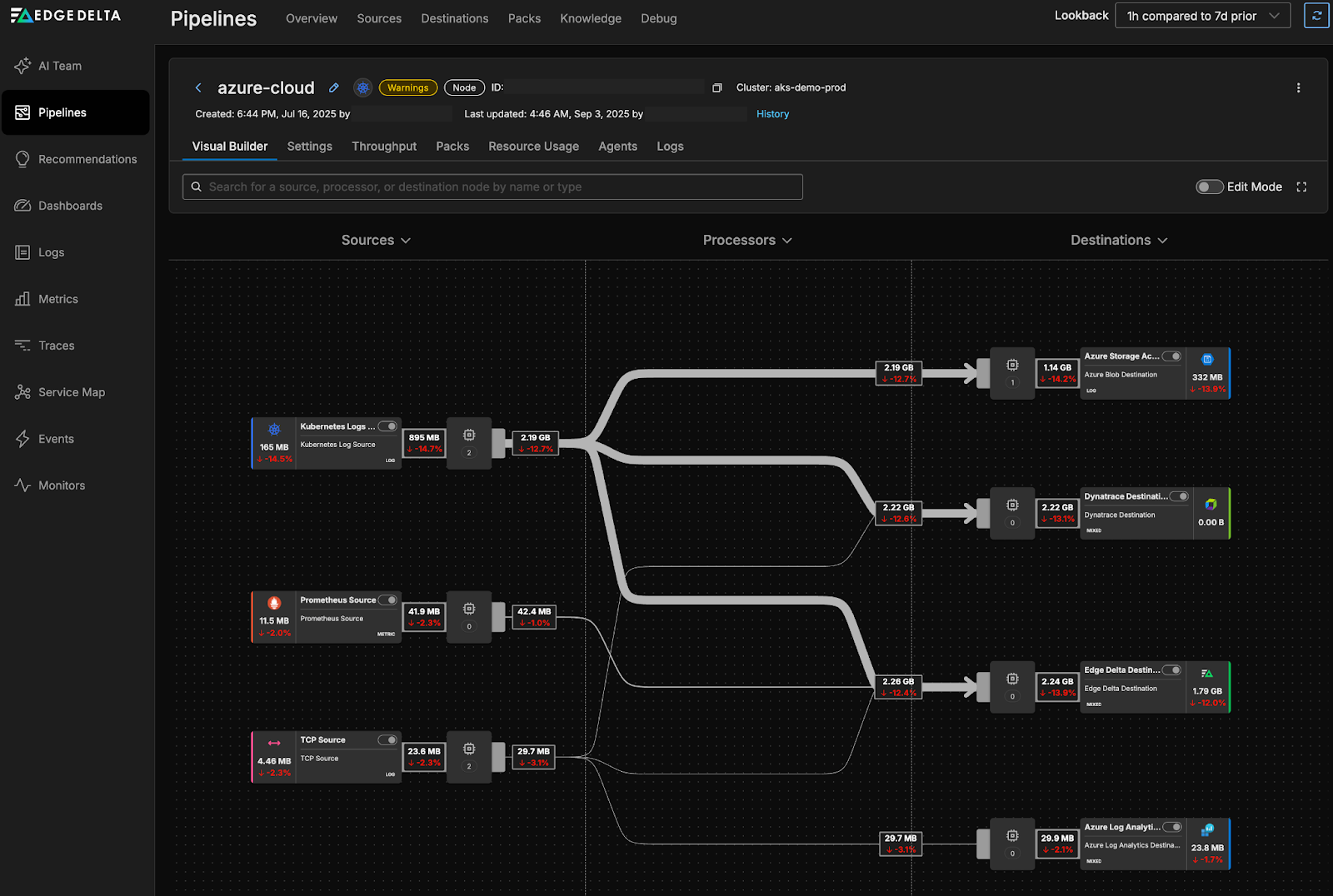
As the name of the company implies, the inline data processing is performed at the edge via an agent installed on the targeted hosts. For a limited number of data sources, it is possible to skip installing the Edge Delta agent and send observability data directly to their cloud. The web dashboard and analysis are hosted on the Edge Delta cloud.
The Edge Delta web dashboard duplicates a lot of the functionality found on observability platforms, including:
The edge processing of the data can perform various transformations depending on configuration. It is possible to configure Edge Delta to forward all data to low-cost storage, such as Amazon S3, and then reduce the data by applying various filters. This reduces the data flow to the observability platform while retaining all data for compliance and/or later use.
The Grepr Intelligent Observability Data Engine uses AI to continuously analyze observability data streams to automatically identify similar patterns in the data. Frequently occurring data is summarized, while unique data is passed straight through. For example, health check requests are summarized, while an error message is passed through. No data is lost when summarized because all data received by Grepr is retained in low-cost storage for compliance and/or later use. The Grepr Intelligent Observability Data Engine currently operates on log and trace data. Support for metrics will be available in the future.

Edge Delta is primarily focused on analysis of observability data streams to provide potential insights and early warning of possible issues. There is the possibility of using the filter processing in defined pipelines to reduce data volumes sent to observability platforms. However, this is not the primary goal.
Grepr is primarily focused on analysis of observability data streams to optimize the volume of data sent to observability platforms. Consequently, increasing the signal-to-noise ratio and controlling platform costs. Existing workflows, dashboards, health rules, etc., remain on the incumbent platform.
Edge Delta is primarily focused on Kubernetes deployment with various Helm charts for the agent daemonset, coordinator deployments, and gateway deployments. Typically, these replace the incumbent agent installs, and pipelines can then ultimately be configured to pass data to the observability platform. This type of installation will require careful planning and consume additional compute resources on the targeted Kubernetes clusters.
Grepr fits in like a shim between the existing observability agents and the platform. The existing agents are reconfigured to send the data to Grepr, where it is processed before being forwarded to the platform. This is not really an installation, just a small reconfiguration of an existing install with minimal impact on the targeted hosts.
Edge Delta pipeline configuration is entirely manual. The sources, sinks, and numerous filters must be manually added and configured for each pipeline. A misconfiguration of a pipeline can result in a significant increase in observability data volume, along with additional egress charges.
Grepr pipeline configuration is more automated. The pipeline source, sink, and data store are configured manually; after that, the AI continuously manages the pipeline. It automatically manages a working set of semantic pattern filters, reducing the data volume by 90% or more. All data received by Grepr is automatically retained in low-cost storage for potential use later.
Both Edge Delta and Grepr have the capability to push retained observability data back into the observability platform to assist in the diagnosis of issues. To provide this functionality Edge Delta requires additional processing components to be installed on the Kubernetes clusters. This functionality is built into Grepr; no additional processing is required to be installed.
To initiate a rehydration or backfill of retained data with Edge Delta, an engineer must create and submit a rehydration job via the web dashboard. Only the source and time period for the rehydration may be selected; all available data for the selected time period will be pushed to the observability platform. This may be considerably more data than is required for the issue under investigation.
Grepr provides the ability to run a query against the retained data using any of the popular syntaxes (Datadog, NewRelic, Splunk) and time period. Once the query is validated, it can be submitted as a backfill job. A more typical use case is to have the backfill triggered automatically via an alert from the observability platform. Grepr can receive a webhook to trigger a targeted backfill.
Edge Delta will take longer to install and configure. Complexity increases due to the duplication of observability platform functionality. Engineers will have two sources of truth: one on the Edge Delta dashboards and one on the existing observability platform. This will have a significant impact on existing workflows and engineer productivity until new working practices are adopted.
Grepr is easier and quicker to configure. There is negligible impact on engineer productivity because existing workflows will continue to be used without disruption. Productivity should increase as a result of the improved signal-to-noise ratio in the observability data, making it easier to find important log messages and non-optimal traces.
The Edge Delta pipeline filters will require continued maintenance of their configuration as services are updated and new ones are deployed. This will consume time and resources.
The Grepr Intelligent Observability Data Engine continuously analyzes the observability data stream and automatically maintains a working set of pattern filters; typically, approximately 200,000 filter rules for high data volumes. Manual intervention is not required.
While the principal goals of Edge Delta and Grepr differ, there are some common features between the two solutions. The AI assistance for querying and issuing notifications provided by Edge Delta is not present in Grepr. However, the pipeline processing and routing of observability data is common to both. Just considering this capability, it is clear that Grepr is the leading solution because it requires minimal initial setup and continuously adapts to changing environments. Grepr does not change existing working practices; it works with them, delivering rapid time-to-value.
For teams that want observability cost control without overhauling existing workflows, Grepr delivers results from day one. There's no complex installation, no manual pipeline maintenance, and no second dashboard competing for your engineers' attention.
Your existing agents, dashboards, and alerting rules stay exactly where they are. Grepr works alongside them, automatically optimizing data volume while retaining everything in low-cost storage for when you need it.
Edge Delta focuses primarily on AI-powered analysis and insights from observability data, with pipeline filtering as a secondary capability. Grepr focuses specifically on optimizing data volume through AI-driven pattern recognition, automatically managing approximately 200,000 filter rules without manual intervention.
Edge Delta requires deploying multiple Helm charts for agent daemonsets, coordinator deployments, and gateway deployments on Kubernetes clusters, replacing existing agent installations. Grepr works as a shim between existing agents and your observability platform, requiring only minor reconfiguration of your current setup.
Edge Delta pipelines require continuous manual maintenance as services are updated and new ones are deployed. Grepr's Intelligent Observability Data Engine automatically adapts to changing environments, maintaining its filter working set without manual intervention.
Edge Delta requires additional processing components and only allows selection by source and time period, pushing all available data for that window. Grepr supports targeted queries using Datadog, New Relic, or Splunk syntax, and can trigger automatic backfills via webhooks from observability platform alerts.
Grepr consistently achieves 90% or greater data reduction through its automatic pattern management. Edge Delta's reduction varies based on manual filter configuration and can potentially result in data volume increases if pipelines are misconfigured.


