
Reduce observability costs by 90%

The Intelligent Observability Data Engine
Stop wasting time optimizing data collection.
Survey
Grepr automatically surveys your dashboards and alerts building a catalog of ‘do not touch’ data.
De-noise
Only high signal information is sent to your observability systems, automatically delivering 90-99% volume reduction.
Persist
No data is lost. Grepr stores every event in low-cost storage. Use your favorite language to query - SPL, Datadog and New Relic Lucene.
Respond
Grepr dynamically adapts to changes in your environment, automatically increasing log granularity and backfilling historical data when incidents occur.
Unlock
Leverage your data set directly from the low-cost storage. Grepr’s standard open-source data formats allow you to use your observability data for business use cases and AI.





Since we deployed Grepr, we’re seeing a 95% reduction in log volume and didn’t have to change a thing in our app. I'd recommend Grepr to any team that's experiencing rising costs from an expensive logging platform
Dave Bortz, VP Engineering, FOSSA
.avif)
It took 20 minutes to set Grepr up, and we immediately saw a 95% drop in log volumes in production! Grepr was the fastest and easiest way for us to get there, and it saved our engineers hours trying to figure out how to do it. Excited to see where Grepr goes next!
Paymahn Moghadasian, Lead Engineer, Goldsky

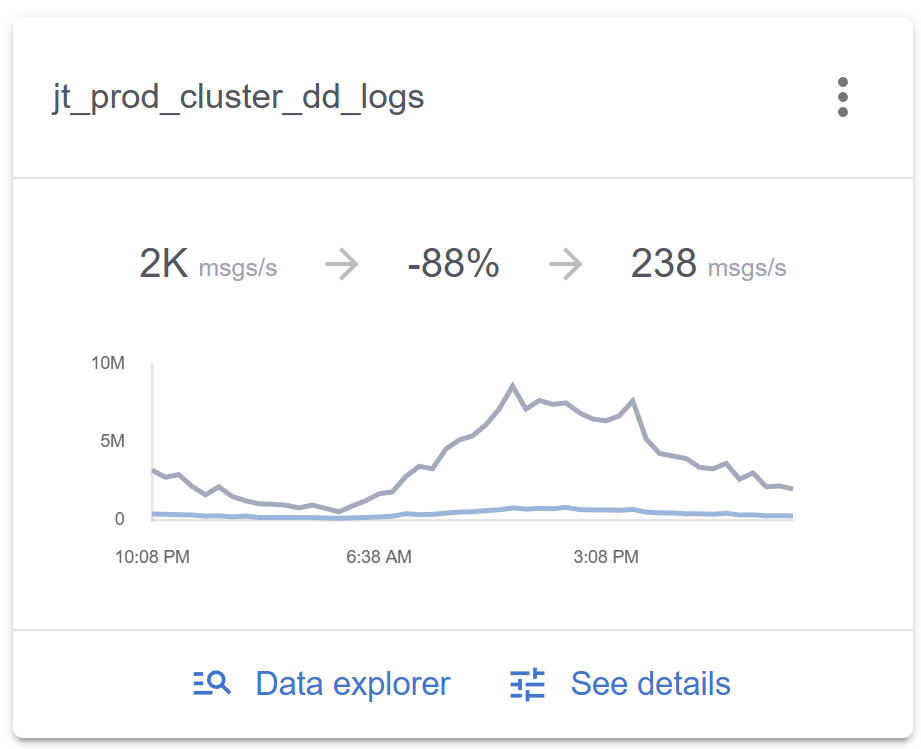
Jitsu handles millions of shipments every month, and each one generates hundreds of logs. Most of them are routine, but we only need to dig in when something goes wrong. Grepr helped us automate what to keep and what to skip, so we’re not paying to store or index noise. It lets us find the needle in the haystack without paying for the haystack.
Evan Robinson, CTO at Jitsu


Enterprise Ready
Grepr seamlessly handles massive scale while meeting the security demands of global enterprises.
- Autoscaling, serverless data processing
Grepr uses infinitely scalable stream processing to handle large and variable ingestion loads.
- SOC2® Type II compliance
Grepr maintains SOC2® compliance, visit our trust center at https://trust.grepr.ai to learn more.
- Single Sign-on with SAML
Support for most SSO providers, including Okta, to simplify user management and compliance.
Get started free and see Grepr in action in 20 minutes.
