Announcements
Announcing the first proactive AI SRE agent
.png)
In my last post, I talked about Observability Debt. We’ve spent a decade using observability as a proxy for reliability, but that proxy has reached its breaking point. We are buried in a mountain of passive data collection that is "too much" to pay for and "too little" to deliver real reliability.
We’ve already cleared the first hurdle: The Data Tax. With our pattern-detection and compression technology, we’ve helped teams reduce their observability costs by at least 75% and often by more than 90%. But saving money on observability is just the beginning.
Today, I’m excited to announce the next leap: The first proactive AI SRE agent. This isn’t just another tool for your stack; it’s an autonomous teammate that understands the intent of your system and acts to protect it.
Almost every AI tool in the reliability market today is reactive. You experience an outage, you find the cause, and you write a rule to ensure that specific problem doesn't catch you off guard again. You are essentially building a library of past failures.
But as complexity and the rate of change accelerate, the rate of “Unknown Uknowns”, failures never before seen in your environment, rapidly increases. If you have to experience a failure to avoid it, you are already too late.
This is the divide between Retrospective AI and Proactive AI:
This is the magic of AI: the ability to generalize from user-provided prompts to what otherwise would have been an infinite number of rules. By shifting from imperative rule-based monitoring to agentic intent-based monitoring, we shift from being reactive to proactive, and stopping incidents before they happen.
This is where the paradigm truly shifts. LLMs enable a move from imperative rules (telling the machine how to monitor) to intent-based monitoring (telling the agent what reliability looks like for your business).
The Grepr Agent doesn't just read logs; it reasons over system state using three proprietary pillars:
Together, these pillars enable Grepr to find new behaviors, monitor emerging issues, and ultimately remediate or alert on them to prevent escalations or incidents.
The most innovative part of the Grepr Agent is its ability to re-configure its own monitoring. If the LLM identifies a suspicious but non-critical pattern, it doesn't just go silent. It can issue a surgical context request: "Monitor the frequency of this specific pattern, and re-trigger this thread if it spikes or if Service B latency exceeds 200ms." The agent builds a context thread, carrying its reasoning forward through time. The context threads taken as a whole form a system memory, learning the idiosyncratic normal of your specific services so it gets smarter over time.
With retriggering, Grepr automatically evolves over time as the application changes and new behaviors emerge, while still maintaining its alignment to the ‘reliability intent’ defined by the engineers.
Imagine a payment system where a transaction spans three services. Usually, the sequence is:
Portal: Payment CommencingProcessor: Payment CompletedPortal: Payment SuccessSuddenly, a new code deployment causes a silent failure. The Processor fails, but the Portal incorrectly assumes success. The new sequence is just steps 1 and 3.
So how do we configure this kind of intent?
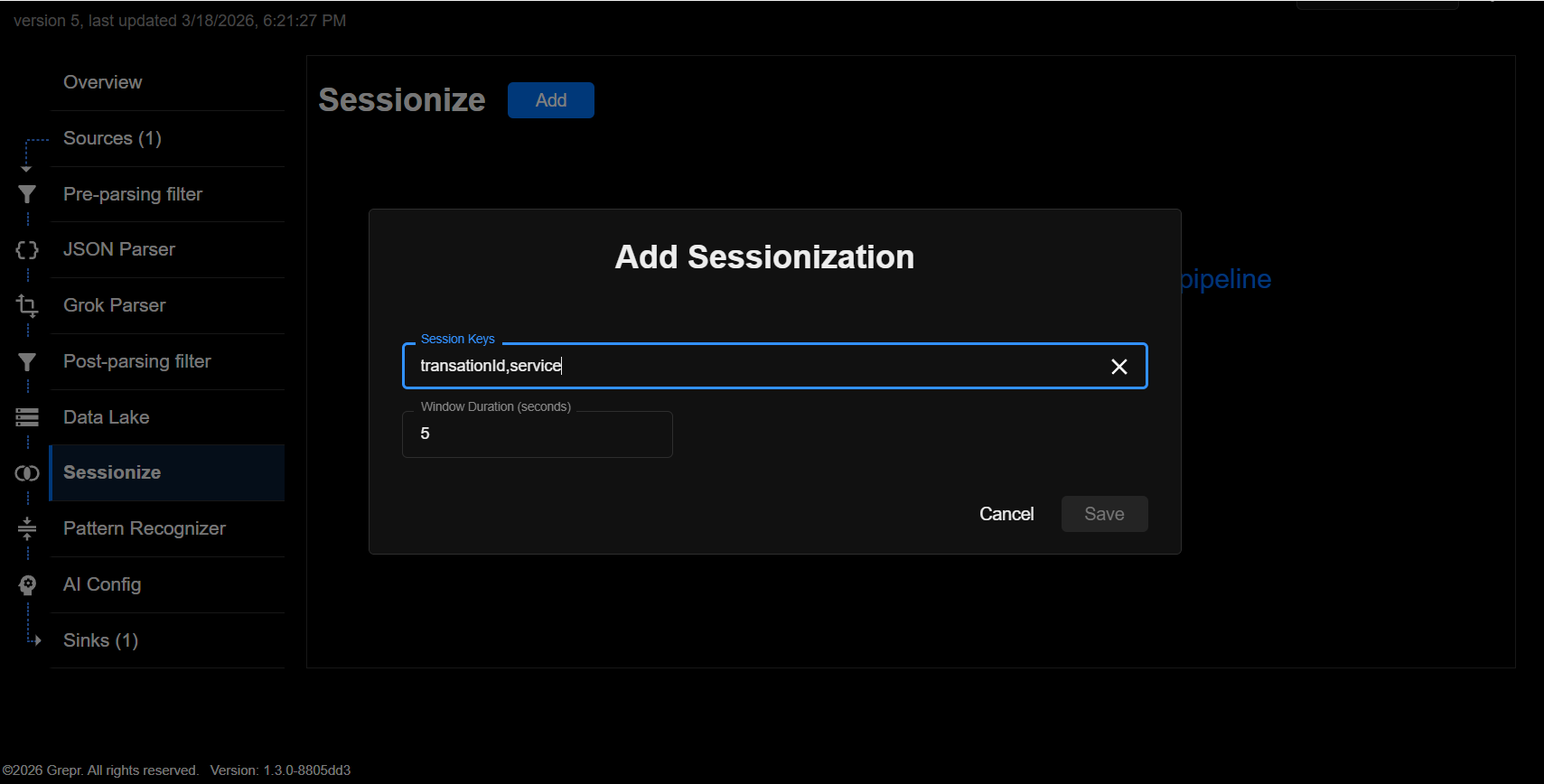
The user configures Grepr to collect data on payment transactions, by specifying a grouping using a transactionId attribute within all log events related to the transaction. These events form an ordered set of logs that are sent to the pattern detector. Grepr can also group data together more loosely based on proximity in time and attributes like IP addresses or others.
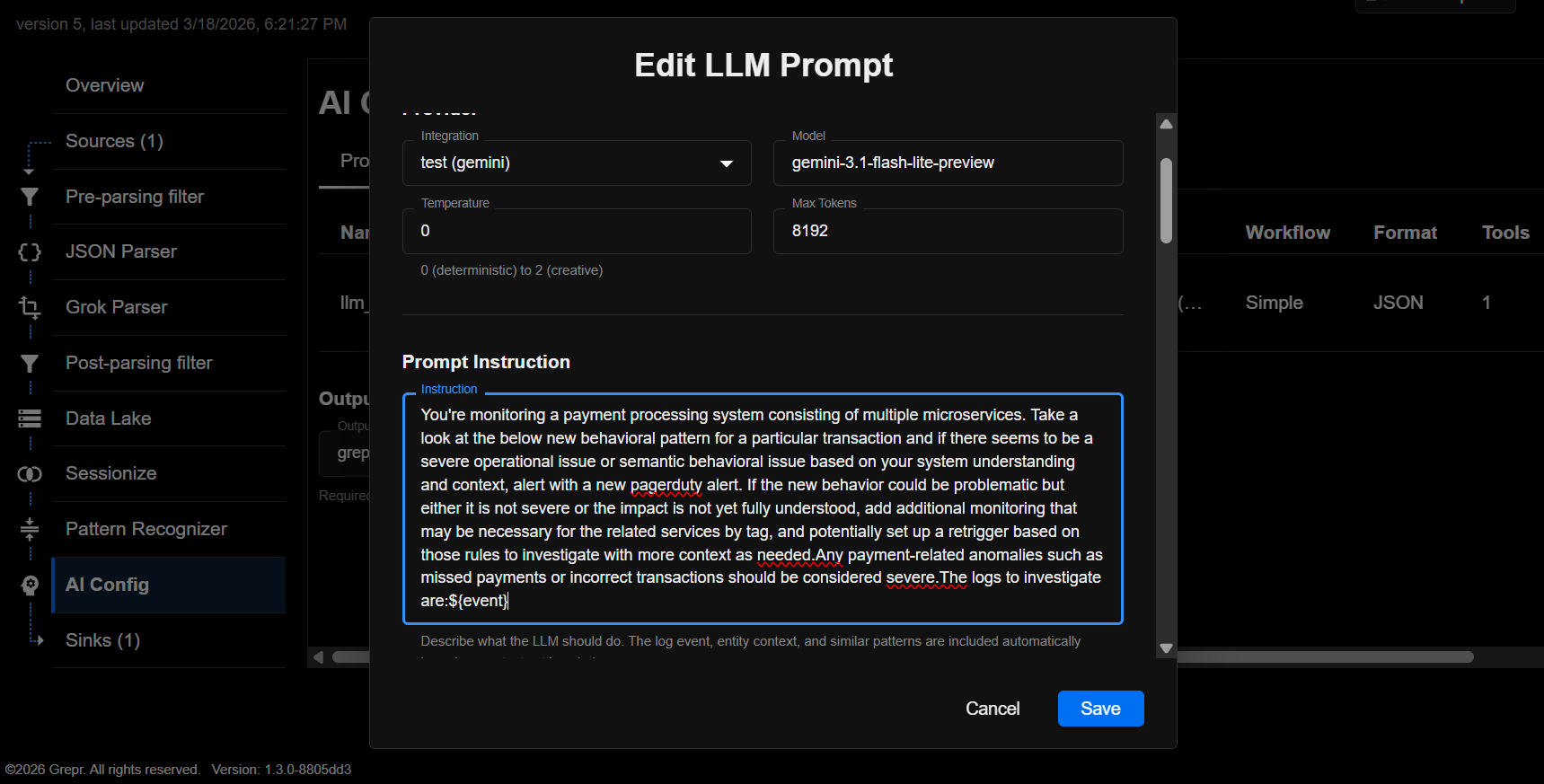
The user configures the following prompt:
You're monitoring a payment processing system consisting of multiple microservices. Take a look at the below new behavioral pattern for a particular transaction and if there seems to be a severe operational issue or semantic behavioral issue based on your system understanding and context, alert with a new pagerduty alert. If the new behavior could be problematic but either it is not severe or the impact is not yet fully understood, add additional monitoring that may be necessary for the related services by tag, and potentially set up a retrigger based on those rules to investigate with more context as needed.
Any payment-related anomalies such as missed payments or incorrect transactions should be considered severe.
The logs to investigate are:
${event}
The user additionally enables following tools for the LLM:
We did not set up individual imperative rules to track different log messages for different services, and we did not force ourselves to think about what are all the possible ways things can go wrong. We only described how to connect dots and what we care about. Even that is going to be simplified as we mature our product.
As software is increasingly run by AI agents, complexity will move beyond human-speed management. We are moving away from being "firefighters" and toward being Architects of Autonomy. Grepr’s Proactive AI SRE Agent empowers engineers to build agents that detect, prevent, and avert incidents in real-time. We are moving away from infinite rule building that fails to anticipate and react to changes, to an intent-based model that enables a completely new operational reliability model.
We aren't just fixing what broke; we’re building systems that don't allow it to break in the first place.
We are currently in a closed beta as we roll this out to our early partners. If you're interested in moving beyond passive observability and building proactive reliability, we’d love to hear from you.
Reach out to us at grepr.ai/contact.
Jad Naous
Founder, Grepr
-----
Most AI SRE tools are reactive chatbots that wait for an incident to occur, then help you analyze what went wrong after the fact. Grepr's agent monitors your environment proactively, detecting behavioral anomalies before they become incidents, without waiting for a threshold to be crossed or a human to ask a question.
Intent-based monitoring lets you describe what reliability looks like for your business in plain English, rather than writing complex scripts or threshold rules for every possible failure. Grepr's agent interprets that intent and monitors your system's behavior accordingly, flagging deviations that match your definition of "misbehavior," not just generic infrastructure alerts.
Grepr uses two complementary technologies: Streaming Stateful SQL stitches together disparate telemetry in real-time to give the AI useful context, and reduces raw event volume by surfacing only meaningful patterns and behavioral changes. Together, they make it computationally and economically viable to run a proactive AI agent against a live data stream.
Yes. Beyond CPU spikes and standard infrastructure anomalies, Grepr can monitor the behavior of complex user workflows, such as checkout flows or multi-step authentication, by joining events across services using shared identifiers like User ID or Trace ID. This allows the agent to detect business-level misbehavior, like a refund that starts but never completes, before the customer notices.
Grepr’s AI SRE agent is currently in closed beta with early partners. You can reach out directly at the contact information provided in the post to discuss joining the beta and moving beyond passive observability toward proactive reliability.


