

Jitsu is a last-mile delivery company focused on providing fast, reliable, and affordable package delivery solutions for e-commerce businesses, particularly in urban areas. Jitsu utilizes proprietary technology for route optimization, driver communication, and real-time tracking, enhancing efficiency and customer experience. Their platform is built from multiple services operating on Kubernetes in the cloud.
Years ago, Jitsu had chosen Datadog for its comprehensive ability to leverage metrics, logs and traces, and the Jitsu DevOps team is quite happy with the solution. Over the years they have built up around 50 custom logging dashboards for monitoring their operations, and the team is well versed in leveraging Datadog for both business and technical operational use cases. However, as the Jitsu platform and business has grown, so have the logging costs.
Jitsu uses their logging system for 3 core use cases; 1) Real-time application troubleshooting, 2) Retrospective investigations of package delivery issues and 3) Continuous compliance validation. These capabilities are foundational to their operations, and their tooling and workflows are well established around Datadog. But therein lies the challenge and the opportunity, how could they reduce the costs of operations without disrupting their established operations?
This is when Evan Robinson, CTO at Jitsu, found Grepr. “Jitsu handles millions of shipments per month and for each shipment, we generate 400 logs. Well over 99% of our shipments are successful, we only need to review logs to understand why a shipment has gone wrong.” This sets up a strong motivation to find a clever way to strip out the non-interesting log data and save money, yet still be able to utilize the established processes and tooling. Evan continued, “we felt that if we could find a solution that balanced between sifting out the redundant and ‘non-interesting’ logs, and could automate that process of deciding what to keep, that would be a very nice approach.”
There was one additional requirement. The log set for each shipment transaction must be archived for 13 months to meet business requirements, so therefore, Jitsu needed to store logs as cheaply as possible, yet still be findable, to meet their compliance needs.
One of the ways Jitsu troubleshoots issues is when an alert fires due to errors in a trace, engineers go to the associated logs. With Grepr reducing logs, what is the impact on that workflow? To mitigate this impact, Jitsu used two features: 1) the trace sampler which passes through full logs for a fraction of the traces Grepr sees, and 2) triggered backfills - when there’s an alert from Datadog on a trace error, Grepr automatically backfills logs for that trace back into Datadog. 99% of the time, the logs that are needed for troubleshooting are already in Datadog, and when not, it’s quick and easy enough to find them in the Grepr Data Lake.
Grepr delivered. Grepr was initially deployed within an hour, and Jitsu saw results within 15 minutes reducing log volume by over 90%. Despite immediate log volume reduction, the impact on their Mean Time To Resolution (MTTR) was "negligible compared to the cost savings” after months of use. Storing logs in their own S3 bucket for compliance was significantly cheaper than within Datadog, with Grepr providing efficient methods for finding specific logs in the archive when needed.
To sum up their feelings, Evan concluded, “Grepr allows us to find the needle in the haystack without paying for indexing the haystack!” We could not have said that any better.
More blog posts
All blog posts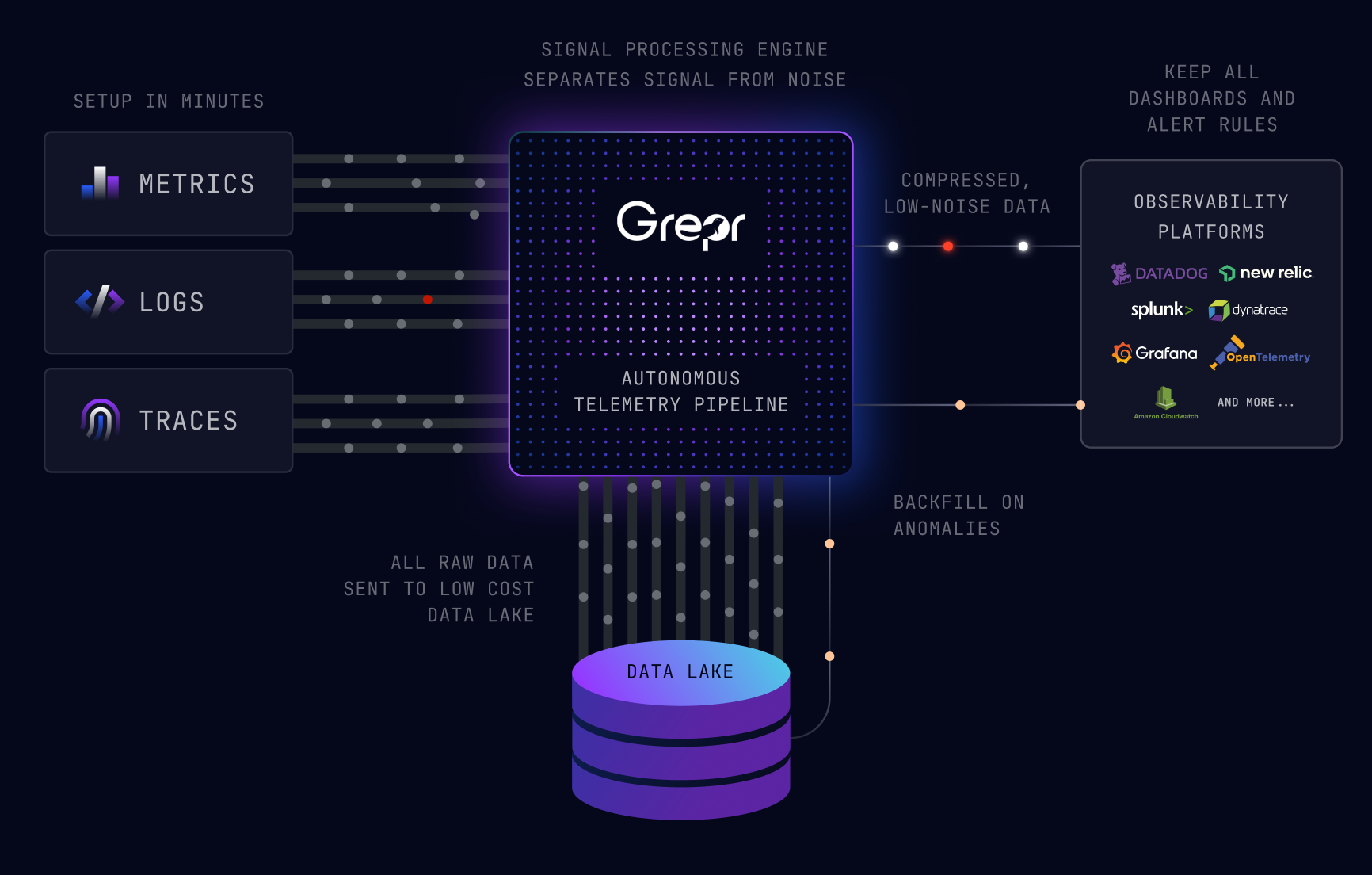
Grepr Just Launched a Free Tier: Reduce telemetry noise by 90%

Grepr Wins the 2026 Intellyx Digital Innovator Award for Observability Cost Reduction

What We Heard at Observability Summit 2026
Get started free and see Grepr in action in 30 minutes.
