

The observability industry loves talking about what comes next. AI-native tooling, automated root cause, self-healing systems. What gets less attention is what happens to the data before it reaches those tools. Almost nobody talks about what happens to the data before it gets there.
There is a layer between your services that emit telemetry and your observability platform that ingests it. That layer is where the data is either useful or expensive noise. And for most organizations, it is expensive noise. The Datadog or Splunk invoice keeps climbing, MTTR stays flat, and engineers spend more time managing their tools than actually debugging production issues.
We built Grepr to sit in that layer. Our ML identifies which patterns in the telemetry stream are just repetition, compresses them, and ensures the anomalous data gets through with low latency. Everything lands in queryable low-cost storage. Your existing tools, dashboards, and alerts do not change. The data feeding them just gets a lot better, and a lot cheaper.
That is our thesis: the future of observability depends on intelligent processing in the telemetry stream itself, before data hits the backend. And a recent LinkedIn post on “Automated Context” from Rishi Kherdekar, a Sr. Engineering Manager at Walmart, is a good example of why.
10x the Data, Zero Extra Insight
Rishi wrote that his team has 10x the data they had five years ago, and they are not solving problems 10x faster. His take on where things need to go covers a lot of ground: alerts that lead to proposed fixes, AI baked into observability tooling by default, systems that can remediate known failures without a human in the loop.
All of those ideas are right. And all of them fall apart if the underlying data is bad; junk in, junk out.
You Cannot Automate Root Cause on Noisy Data
Rishi wants systems that propose fixes, not just alerts. So does every SRE who has ever dismissed 200 alerts before lunch. Dashboard fatigue is something the industry has normalized without ever actually doing anything about it.
The problem is that root cause analysis depends on separating signal from noise at the telemetry level, and most environments have a terrible signal-to-noise ratio. Millions of repetitive heartbeat logs, all saying "yep, still running," bury the handful of messages that actually tell you something broke. An AI engine pointed at that dataset is going to spend most of its compute chewing through the boring stuff. "Garbage in, garbage out" does not stop applying just because the garbage disposal got upgraded to a large language model.
Before any AI-driven root cause engine can do its job, something in the pipeline needs to identify which telemetry is repetitive, summarize it, and surface the anomalous data with low latency. That preprocessing layer is the prerequisite that teams just do not currently have.
AI-Native Observability Has a Cost Problem
Rishi predicts AI will become table stakes in observability. He is right, but most teams will hit a wall when they get there: running AI on top of bloated, noisy telemetry is expensive and slow.
If you are paying per-GB rates to keep everything in a hot tier so your AI engine can analyze it, you have traded one cost problem for two. The observability data bill stays high, and now, in addition, there is a compute bill for the AI layer sitting on top of it.
What works better is putting ML in front of your observability platform. Let it figure out which patterns in the telemetry stream are repetitive, compress those down, and pass through the stuff that is actually worth analyzing. You do not lose data this way. Everything still lands in low-cost storage. Your expensive tools and AI engines just stop wasting cycles on telemetry data that was never going to tell you anything useful.
Self-Healing Systems Need Data They Can Trust
Rishi's point about autonomous remediation is one of the most interesting parts of his post, and also the one with the highest bar for data quality. For a system to take automated action on a known failure pattern, it needs extremely high confidence that it correctly understands what is happening. An auto-remediation workflow that fires on a false positive because the underlying data was too noisy does more damage than the incident it was attempting to fix.
Strong signal-to-noise ratio and anomalies surfaced with context let autonomous systems operate confidently. An undifferentiated firehose of telemetry turns auto-remediation into a liability that creates incidents instead of resolving them.
The Layer That Makes All of This Work
Rishi's post ends by saying the goal is no longer reliability; it is clarity. We agree, and we think clarity starts in the telemetry stream.
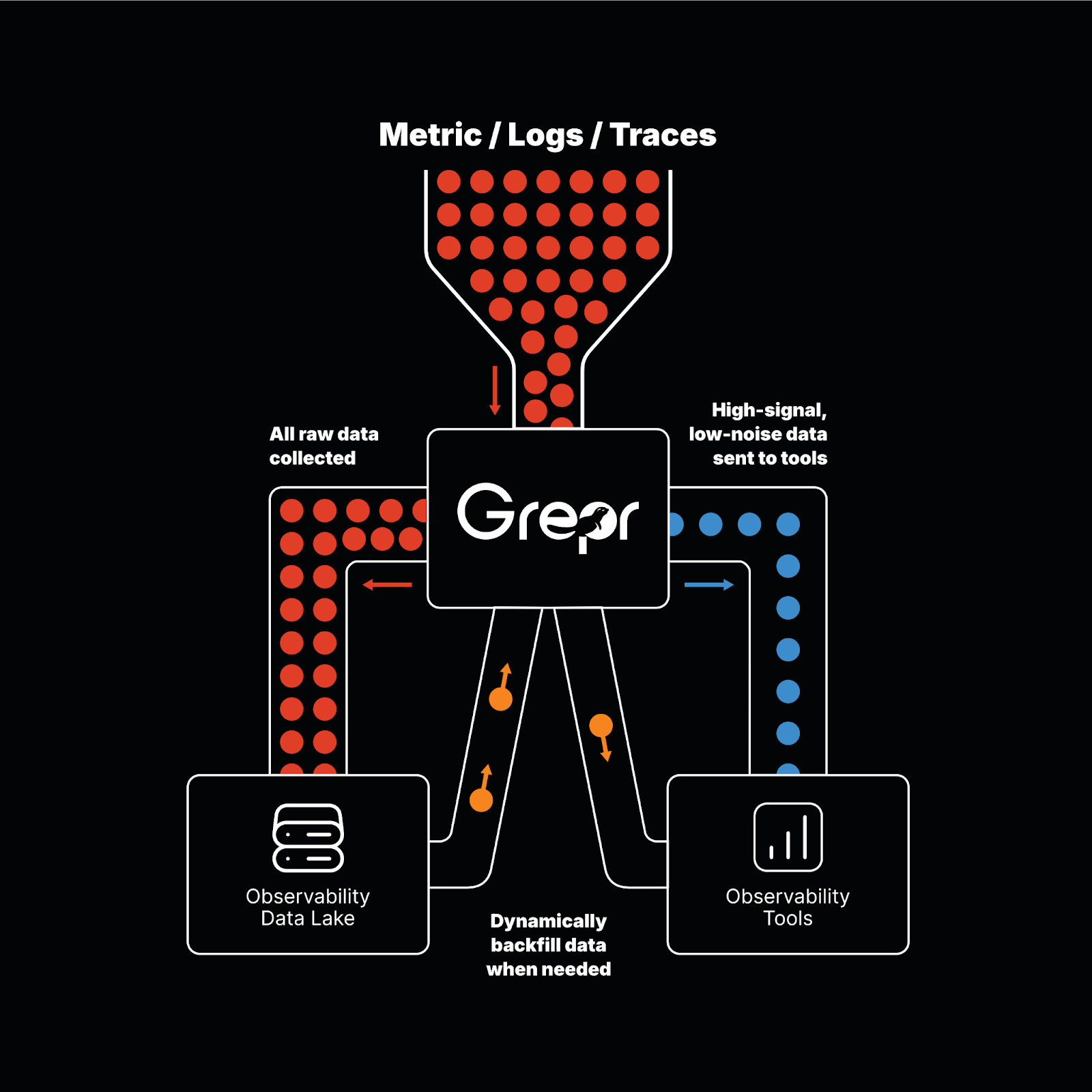
Grepr sits between your services and your observability platform. We use machine learning to identify patterns, summarize repetitive data, surface anomalies, and store everything in queryable low-cost storage. No configuration changes, no disruption to workflows. A $2 million observability bill drops to $200K without losing a single alert or dashboard. Your engineers get cleaner data, and your team gets their budget back.
The teams that will be ready for the shifts Rishi describes are the ones solving the data problem now. Not by collecting less, but by making what they collect worth looking at.
Frequently Asked Questions
1. Why does AI-powered observability fail on noisy telemetry data?AI-driven root cause analysis and automated remediation depend on high signal-to-noise ratios in your telemetry stream. When millions of repetitive logs bury the anomalous data that actually matters, AI engines waste compute cycles processing noise instead of identifying real issues. Preprocessing telemetry before it reaches your observability platform gives AI tools cleaner input and faster, more accurate results.
2. How can organizations reduce observability costs without losing data?Instead of dropping telemetry or downsampling blindly, machine learning in the telemetry pipeline can identify repetitive patterns, compress them, and route everything to queryable low-cost storage. Anomalous data passes through to your existing tools with low latency. You keep full coverage while dramatically reducing per-GB ingestion costs at platforms like Datadog or Splunk.
3. What is a telemetry preprocessing layer in observability?A telemetry preprocessing layer sits between the services emitting logs, metrics, and traces and the observability backend that ingests them. It analyzes data in the stream to identify patterns, summarize repetitive telemetry, surface anomalies, and route data to appropriate storage tiers. This layer improves data quality and reduces costs before anything hits your observability platform.
4. Why does dashboard fatigue persist even with more observability data?Collecting more telemetry without processing it intelligently creates more noise, not more insight. Teams end up with thousands of alerts triggered by repetitive, low-value data, and engineers spend their time managing tools instead of debugging production issues. Improving the signal-to-noise ratio at the pipeline level reduces alert volume and surfaces the data that actually indicates problems.
5. What data quality is required for self-healing observability systems?Autonomous remediation systems need extremely high confidence that they correctly understand what is happening in production before taking automated action. That confidence requires clean telemetry with strong signal-to-noise separation and anomalies surfaced with context. Without that data quality, auto-remediation risks firing on false positives and creating new incidents instead of resolving existing ones.
More blog posts
All blog posts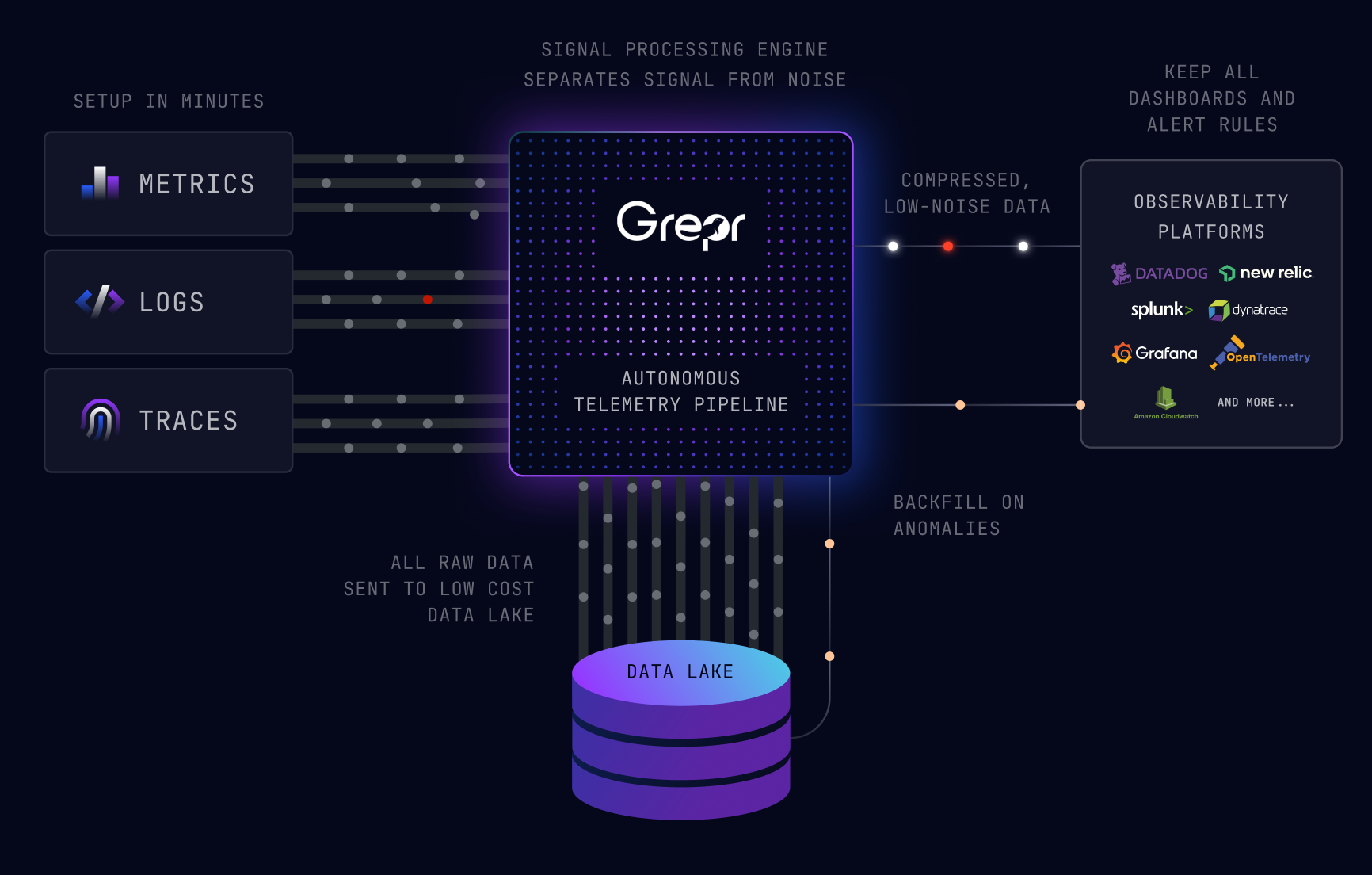
Grepr Just Launched a Free Tier: Reduce telemetry noise by 90%

Grepr Wins the 2026 Intellyx Digital Innovator Award for Observability Cost Reduction

What We Heard at Observability Summit 2026
Get started free and see Grepr in action in 30 minutes.
